The real benefits of end-to-end observability (Sponsored)
How does full-stack observability impact engineering speed, incident response, and cost control? In this eBook from Datadog, you’ll learn how real teams across industries are using observability to:
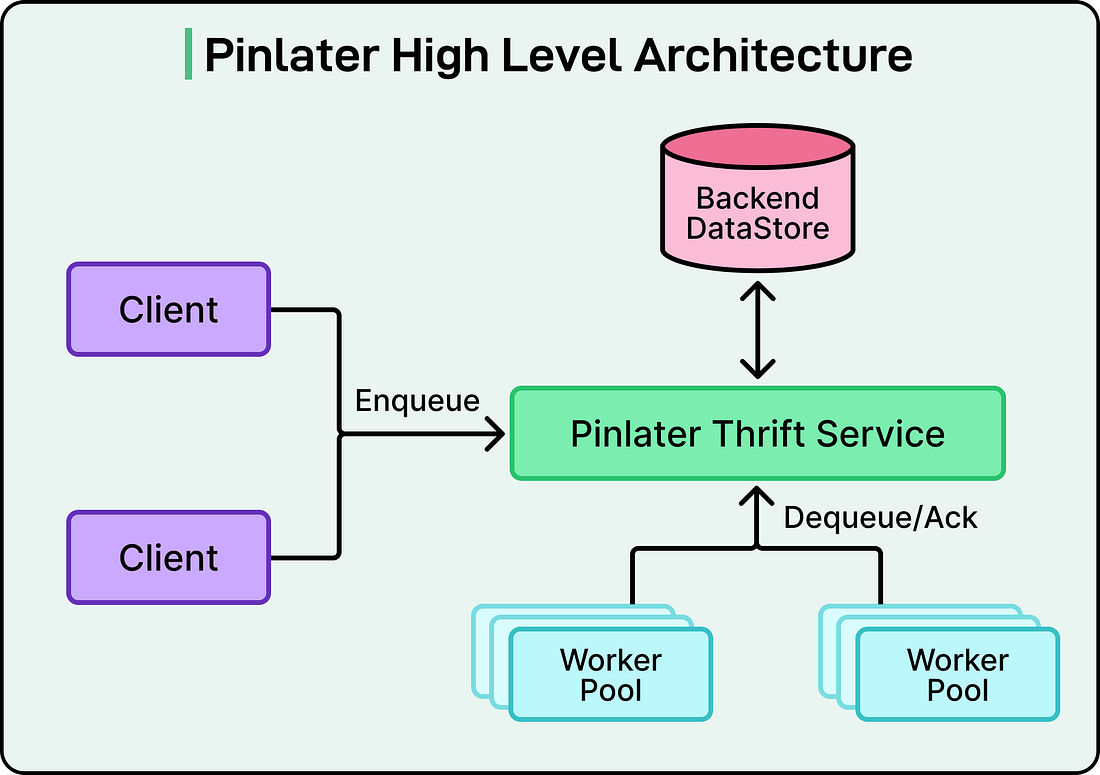
See how unifying your stack leads to faster troubleshooting and long-term operational gains. When Pinterest’s engineering team built their asynchronous job processing platform called Pinlater a few years ago, it seemed like a solid solution for handling background tasks at scale. The platform was processing billions of jobs every day, powering everything from saving Pins to sending notifications to processing images and videos. However, as Pinterest continued to grow, the cracks in Pinlater’s foundation became impossible to ignore. Ultimately, Pinterest had to perform a complete architectural overhaul of its job processing system. The new version is known as Pacer. In this article, we will look at how Pacer was built and how it works. Disclaimer: This post is based on publicly shared details from the Pinterest Engineering Team. Please comment if you notice any inaccuracies. What Asynchronous Job Processing DoesBefore examining what went wrong with Pinlater and how Pacer fixed it, we need to understand what these systems actually do. When you save a Pin on Pinterest, several things need to happen. The Pin needs to be added to your board, other users may need to be notified, the image might need processing, and analytics need updating. Not all of these tasks need to happen instantly. Some can wait a few seconds or even minutes without anyone noticing. This is where asynchronous job processing comes in. When you click save, Pinterest immediately confirms the action, but the actual work gets added to a queue to be processed later. This approach keeps the user interface responsive while ensuring the work eventually gets done. See the diagram below that shows an async processing approach on a high level:
The job queue system needs to store these tasks reliably, distribute them to worker machines for execution, and handle failures gracefully. At Pinterest’s scale, this means managing billions of jobs flowing through the system every single day. Why Pinlater Started StrugglingThe Pinterest engineering team built Pinlater around three main components.
See the diagram below:
This architecture worked well initially, but several problems emerged as Pinterest’s traffic grew. The most critical issue was lock contention in the database. Pinterest had sharded their database across multiple servers to handle the data volume. When a job queue was created, Pinlater created a partition for that queue in every single database shard. This meant that if you had ten database shards, every queue had ten partitions scattered across them.
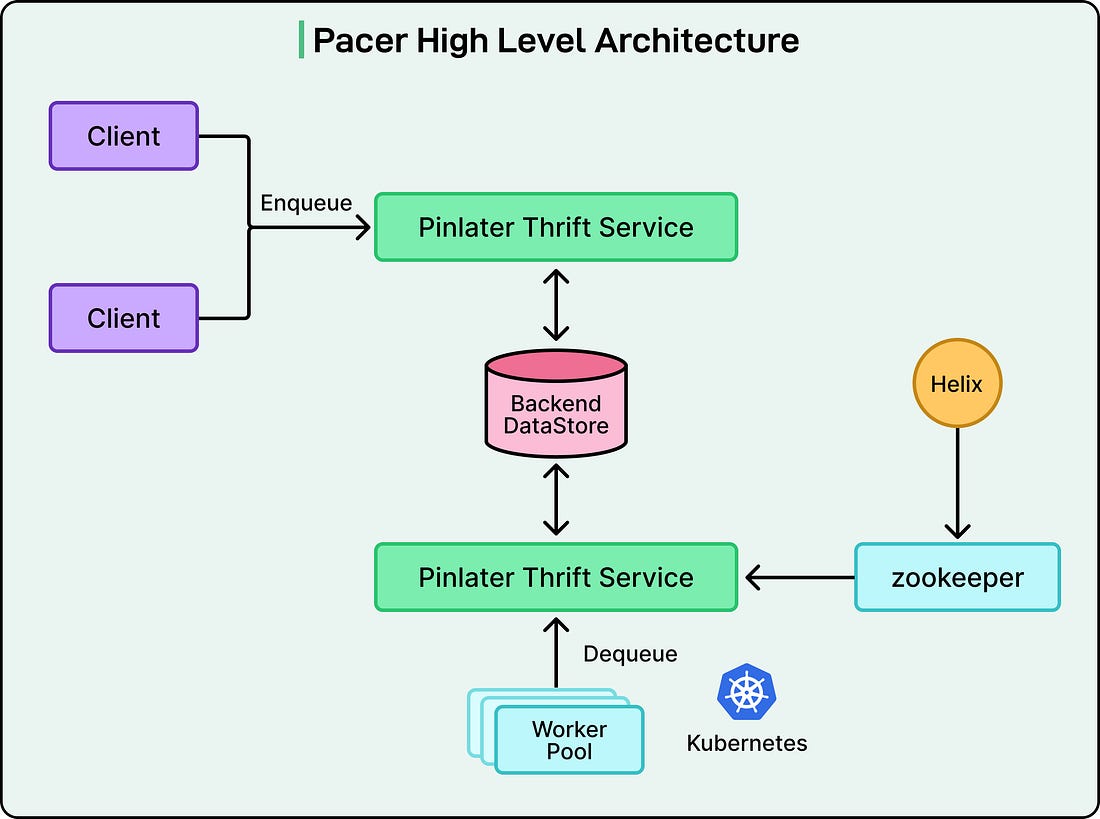
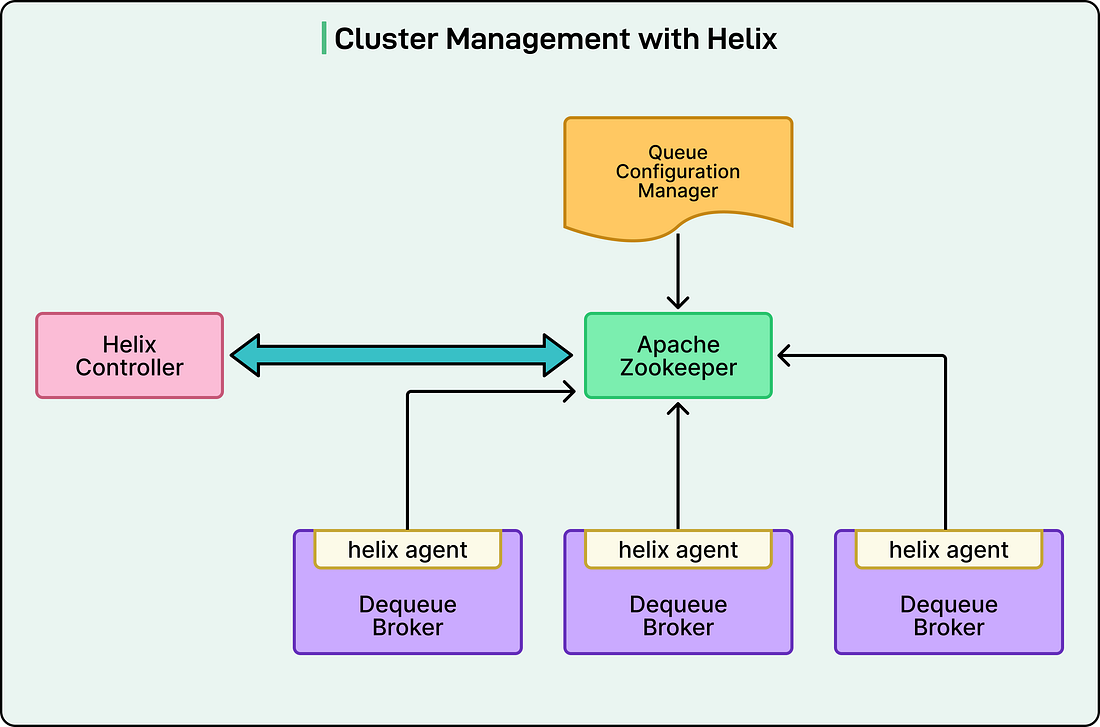
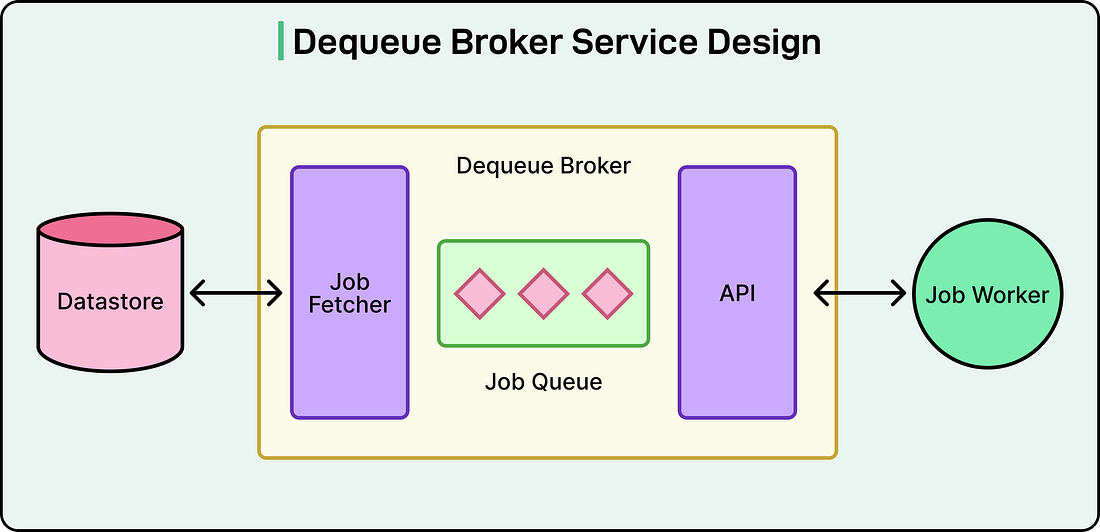
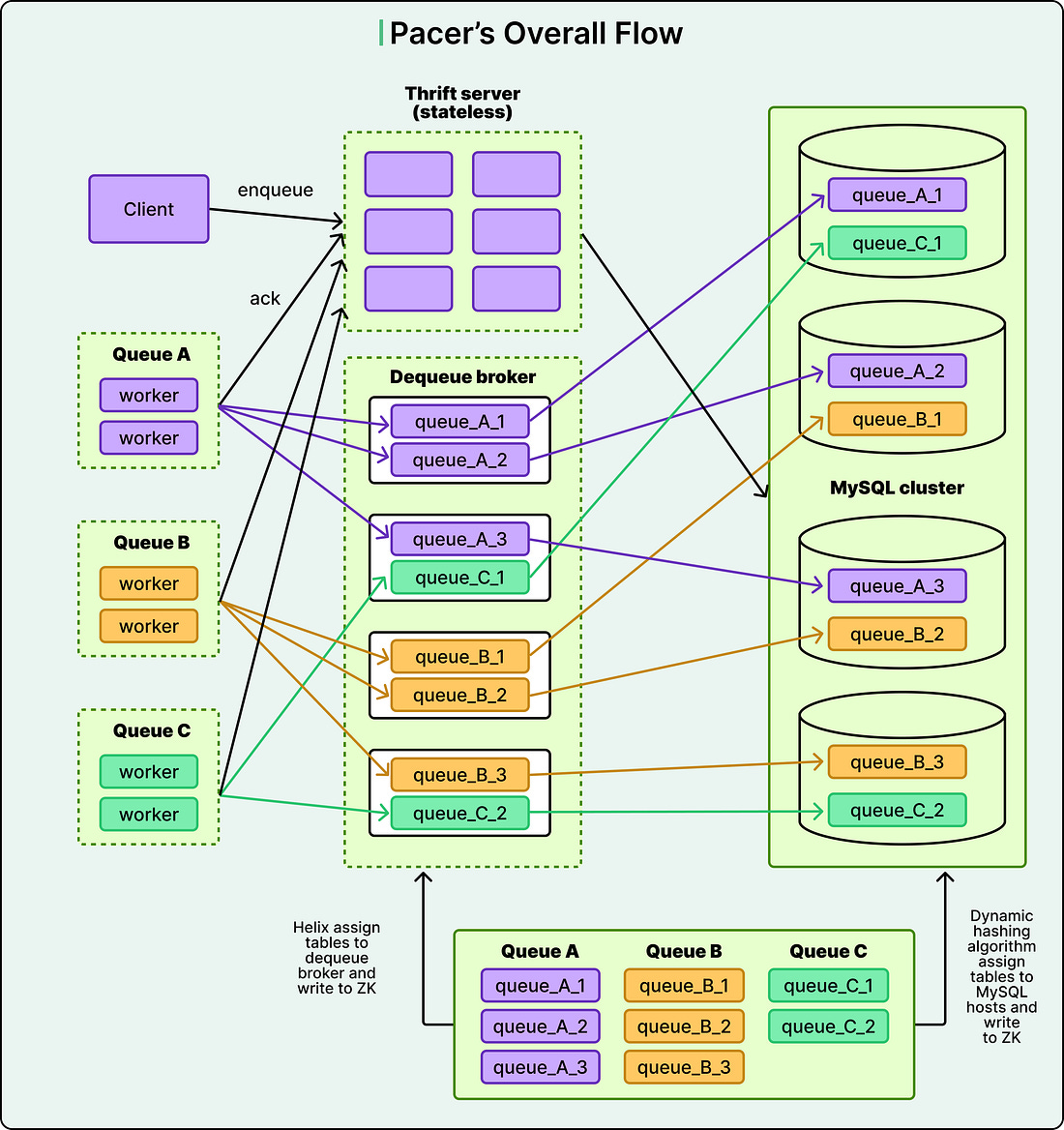
When workers needed jobs to execute, the Thrift service had to scan all the shards simultaneously because it did not know in advance which shards contained ready jobs. This scanning happened from multiple Thrift servers running in parallel to handle Pinterest’s request volume. The result was dozens of threads from different Thrift servers all trying to read from the same database partitions at the same time. Databases handle concurrent access using locks. When multiple threads try to read the same data, the database coordinates this access to prevent corruption. One thread gets the lock and proceeds while others wait in line. At Pinterest’s scale, the database was spending more resources managing these locks and coordinating access than actually retrieving data. As Pinterest added more Thrift servers to handle growing traffic, the lock contention worsened. The second major issue was the complete lack of isolation between different job queues. Multiple queues with vastly different characteristics all ran on the same worker machines. A queue processing CPU-intensive image transformations shared resources with a queue sending simple notification emails. If one queue had a bug that crashed the worker process, it took down all the other queues running on that machine. Performance tuning was nearly impossible because different workloads needed different hardware configurations. The third problem was that different operations in the system had very different reliability requirements, but they all shared the same infrastructure. Enqueueing jobs was part of critical user-facing flows. If the enqueue operations failed, users would notice immediately. Dequeue operations, on the other hand, just determined how quickly jobs got processed. A brief delay in dequeuing meant jobs took a few extra seconds to run, which was usually acceptable. However, both operations competed for resources on the same Thrift servers, meaning less critical operations could impact critical ones. Finally, the way Pinlater partitioned data across shards was wasteful. Even tiny queues with minimal traffic got partitions in every database shard. The metrics showed that more than half of all database queries returned empty results because they were scanning partitions that held no data. The system also could not support FIFO ordering across an entire queue because jobs were processed from multiple shards simultaneously, with no way to maintain global ordering. The Pacer SolutionRather than trying to optimize around these problems, the Pinterest engineering team decided to rebuild the system from scratch. Pacer introduced several new components and fundamentally changed how data flowed through the system. The biggest change was the introduction of a dedicated dequeue broker service. This stateful service layer sits between the workers and the database, and it changes how jobs are retrieved. Instead of many Thrift servers all competing to read from the database, each partition of each queue is assigned to exactly one dequeue broker instance. This assignment is managed by Helix, a cluster management framework that Pinterest integrated into the system. See the diagram below:
Here is how the assignment process works:
See the diagram below:
The assignment approach eliminates the lock contention problem. Since only one broker ever reads from a given partition, there is no competition at the database level. However, the dequeue broker does more than just eliminate contention. It also improves performance through caching. Each broker proactively fetches jobs from its assigned partitions and stores them in in-memory buffers. These buffers are implemented as thread-safe queues. When workers need jobs, they request them from the broker’s memory rather than querying the database. Memory access is orders of magnitude faster than database queries, and Pinterest’s metrics show dequeue latency dropped to under one millisecond. See the diagram below:
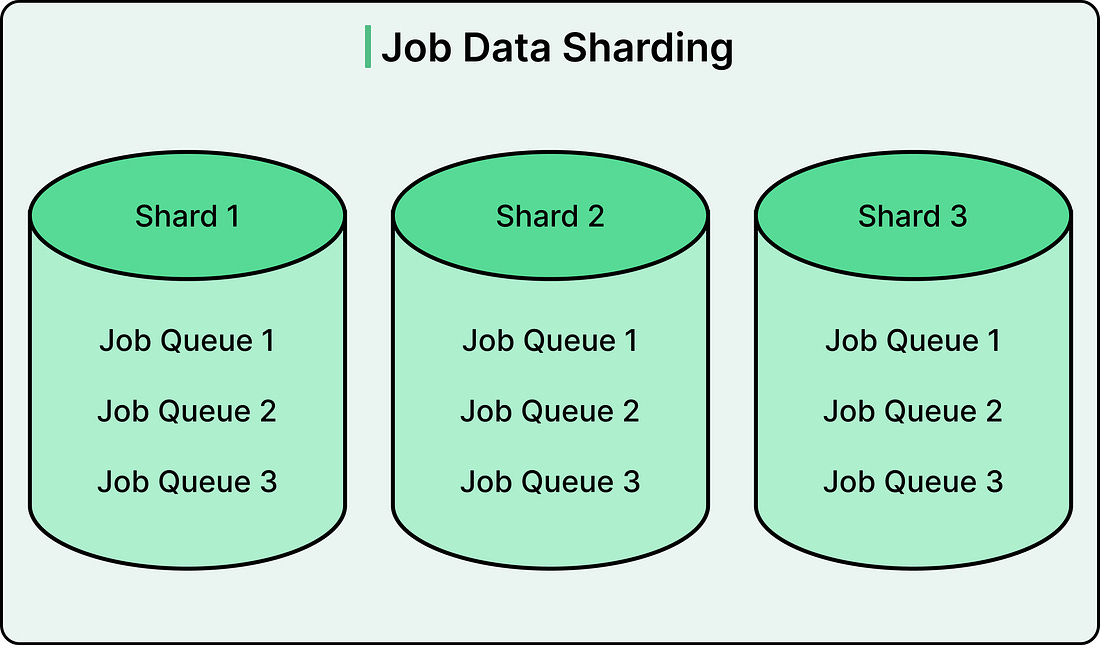
Pinterest also completely rethought how queues are partitioned across database shards. In Pinlater, every queue had partitions in every shard, regardless of its size or traffic. Pacer takes a different approach.
This adaptive sharding eliminated the resource waste that was a problem in Pinlater. The percentage of empty query results dropped from over 50% to nearly zero. See the diagram below:
This flexible partitioning also enabled new features. FIFO ordering, which was impossible in Pinlater, became possible in Pacer. A queue that needs strict ordering can be configured with a single partition, guaranteeing that jobs are processed in the exact order they were submitted. Also, for job execution, the Pinterest engineering team moved from shared worker pools to dedicated pods running on Kubernetes. Each queue now gets its own isolated worker environment with custom resource allocations. For example, an image processing queue can be configured with high CPU and moderate memory. A notification queue can use low CPU and memory but high concurrency settings. One queue’s problems cannot affect others, and each queue can be tuned for optimal performance on hardware matched to its specific needs. The separation of concerns extends to the request path as well. In Pacer, the Thrift service handles only job submission. This critical, user-facing path is completely isolated from dequeue operations. Even if the dequeue brokers experience problems, users can still submit jobs without noticing any issues. The jobs might take longer to process, but the submission itself remains fast and reliable. ConclusionThe migration from Pinlater to Pacer delivered measurable improvements across multiple dimensions.
From a system design perspective, the Pacer architecture demonstrates several important principles.
References:
SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
|



0 💬:
Post a Comment